Blogging Is Hard
It’s Not Easy
Even the biggest of giants can’t do it. I always love to make fun of the bigger tech companies. Ever since this site went up I feel like I’ve been bashing Google’s documentation (rightly so). But a while ago (May-17 2021) I found something that really made me realize just how many mistakes are out there.
Oracle: apparently lacking foresight
I like to keep up to date with tech, and recently I was working a lot on Oracle’s tech stack. I found a few blog aggregators, think hackernews or Reddit, except they’re much more.. Eh well let’s just say they’re focused on business.
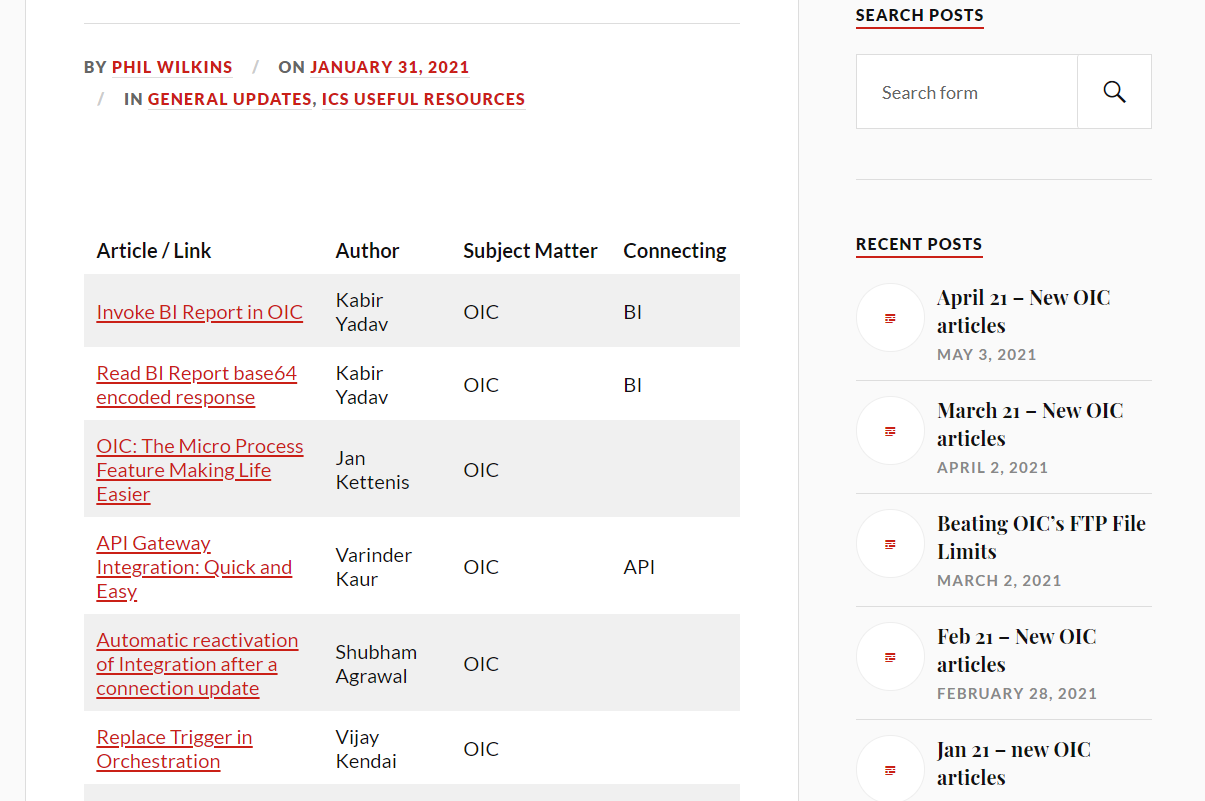
here's a lot of good articles right?
Anyway, peel away the veneer of stock photos of buildings some people probably work and “live” in and there’s some genuinely helpful content hidden in these articles. I saw in this aggregator of news this article:
“automatic reactivation of Integration after a connection update” Awesome I thought. Well not so awesome, what I’m sure pointed to a perfectly good article in the past now points nowhere. “It’s Dead Jim”
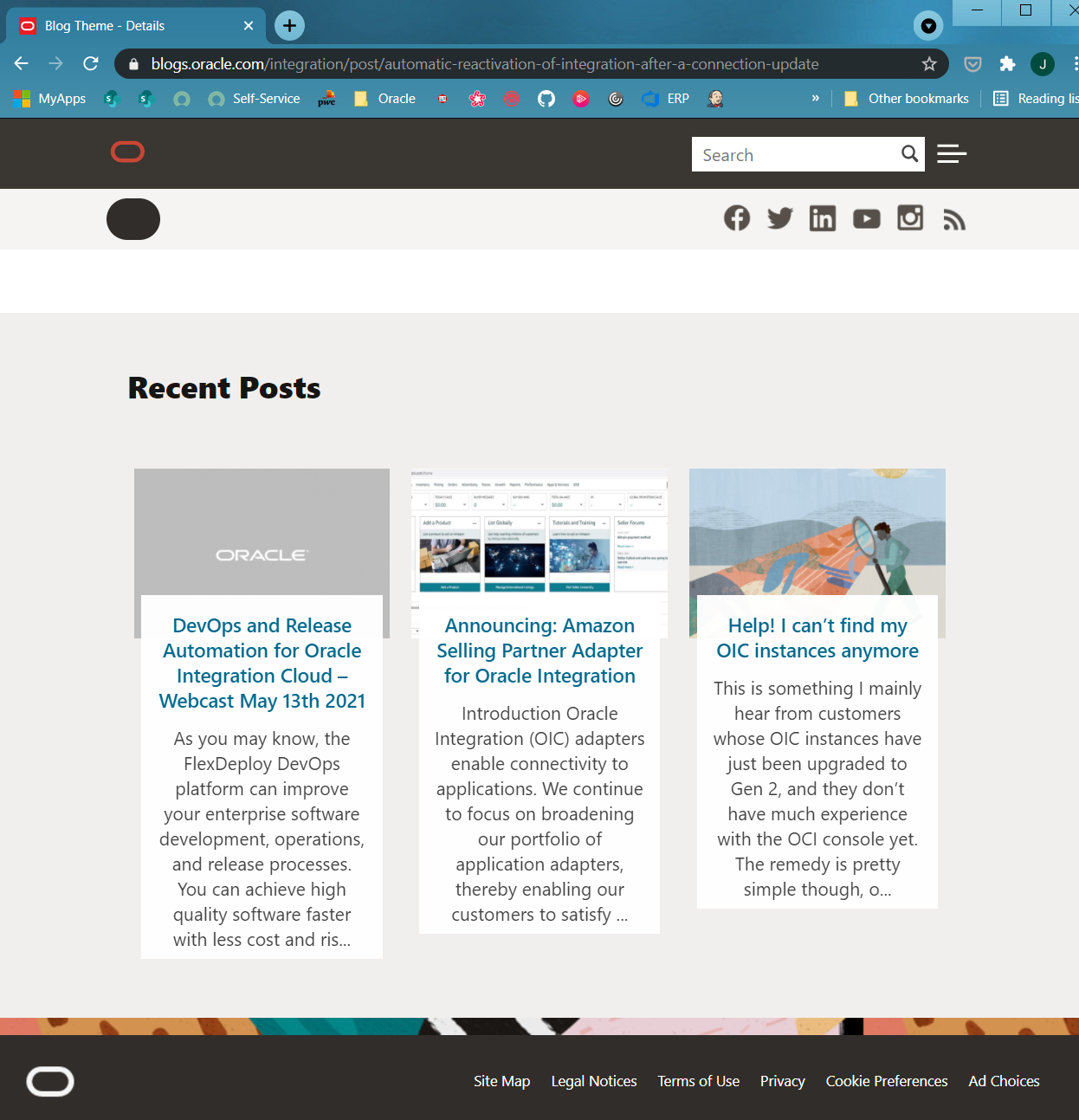
There should be an article here
The Dreaded Dead Links
This is an issue with any blogging site. Consider that URL’s are the user interface (thanks Scott). If you believe in this premise, then you also want to have your URL say something.
Oracle seems to believe this but there’s a dark side to doing this. You see, if I want to post an article called “Why I love Avocados so much” and I only wanted to do it once, well there’s no problem. But what if I wanted to do “Why I love Avocados so much” and I forgot to tack a part 2 on there, or I decided that “part 2” was a bit corny. Well, you better hope no one linked to the old article because now 1 of 2 things happened:
- Your system complained that you messed up, you fixed it before you made a mistake on the internet (annoying but helpful)
- One of your articles doesn’t work because they’re both trying to get to the same domain (potentially pretty disastrous)
And all you did was try to make the URL not read ‘post/5531’
Scott also mentions a cool thing that Stack Overflow does that I wish I did: they have an identifier and then a readable part to their URL’s. Neat! This also means that you don’t have to worry if someone changes their name, their title, etc. etc. As long as that number you pulled out of thin air stays the same, everything is good.
This isn’t an easy thing to do - or at least it seems so. A lot of big companies mess this up - it’s not just Oracle. This Reddit thread complains about the same thing.. I wonder if Reddit has the same problem? Stack Overflow says this too.
When I tried looking for examples from Google I was pleasantly surprised, I even tried using Bing to avoid any search engine bias. Maybe Google pads their stats, or maybe Bing doesn’t index Reddit? Either way, dead links are a huge problem for organizations of any size.

zombies swarm: we learned this from Night of the Living Dead
Dead links are like zombies - once they’re out there they spread and there’s nothing you can do about it unless you take a lot of time and effort to get rid of every copy or have some clever inoculation technique (like good redirects). If the infection gets too bad then people are hitting your domain with bogus requests, and they think that your site is a zombie… and maybe it is; if you’re pumping the internet with dead links, your site is going to shrivel up and shamble on. If you’re running a website, and you intend for your site to be usable, consider that every link you publish should live forever… like a vampire not a zombie.
What if I already messed up
Sam at clickstocode.dev already did! He found out that Google does this thing where they go through your site, save the URL’s and save the content in something of a huge cache. This is necessary to make a search engine, and ultimately it hurts you if your goal is to get users clicking on your articles.

This link used to lead somewhere
Why? Well, when Sam set up his site, he used a pretty standard URL schema: every
blog post is under the root directory. There’s nothing wrong with this, but
when he changed to use the /blog route for his posts… Well when Google
crawled and cached his site, he didn’t have that. And now he’s got the acute
problem of Google linking to a 404 page.
Ouch…
I’m not as well read on this topic as I’d like to be. What do you do if you’ve already let the dead links out?
You can try to 301 / 302 things, by which I mean you can set up your site to automatically redirect those dead links. This works fine (beware the dreaded Cross-site upgrade trap), and it’s usually your only option if a large search engine has already found your bad links. Managing these bad links is a whole project unto itself, and from the looks of it, no one has really solved it.
Avoiding Linking the Dead
I’ve already missed my chance to have the perfect URL system because I, like so many others, didn’t quite plan ahead. What I did do was start using permalinks that are based on the original post date, and I don’t change that. So worst-case scenario, if I ever have to relabel an article for some reason (I don’t really know why yet, but I’m sure I will find out!) then I can still have a permanent link that will not change…
You might notice that this doesn’t quite satisfy the ultimate usability threshold that Stack Overflow gave with their nifty user ID trick, but it gets pretty close. In my site, I tend to use this because I change my mind, titles change, and I figure out better pithier statements to go in my favorite articles. But when I read his first article then it came back up, it stuck in the back of my head like something you always gotta do.
Now rereading how Stack Overflow does it, I’m curious: how do you do this in Hugo? Maybe I’ll dive into this later on. For now what I do is set a bunch of aliases in the frontmatter for my Hugo posts. If you’re not using Hugo, then YMMV, but here’s the frontmatter for this page.
title: "Blogging Is Hard"
slug: "blogging-is-hard"
date: 2021-07-25
alias: ["post/2021-07-25", "blogging-is-hard", "post/2021/blogging-is-hard"]
On the bright side, it’s not rare and if you’ve messed up, then you’re in the same company as Oracle and Microsoft!